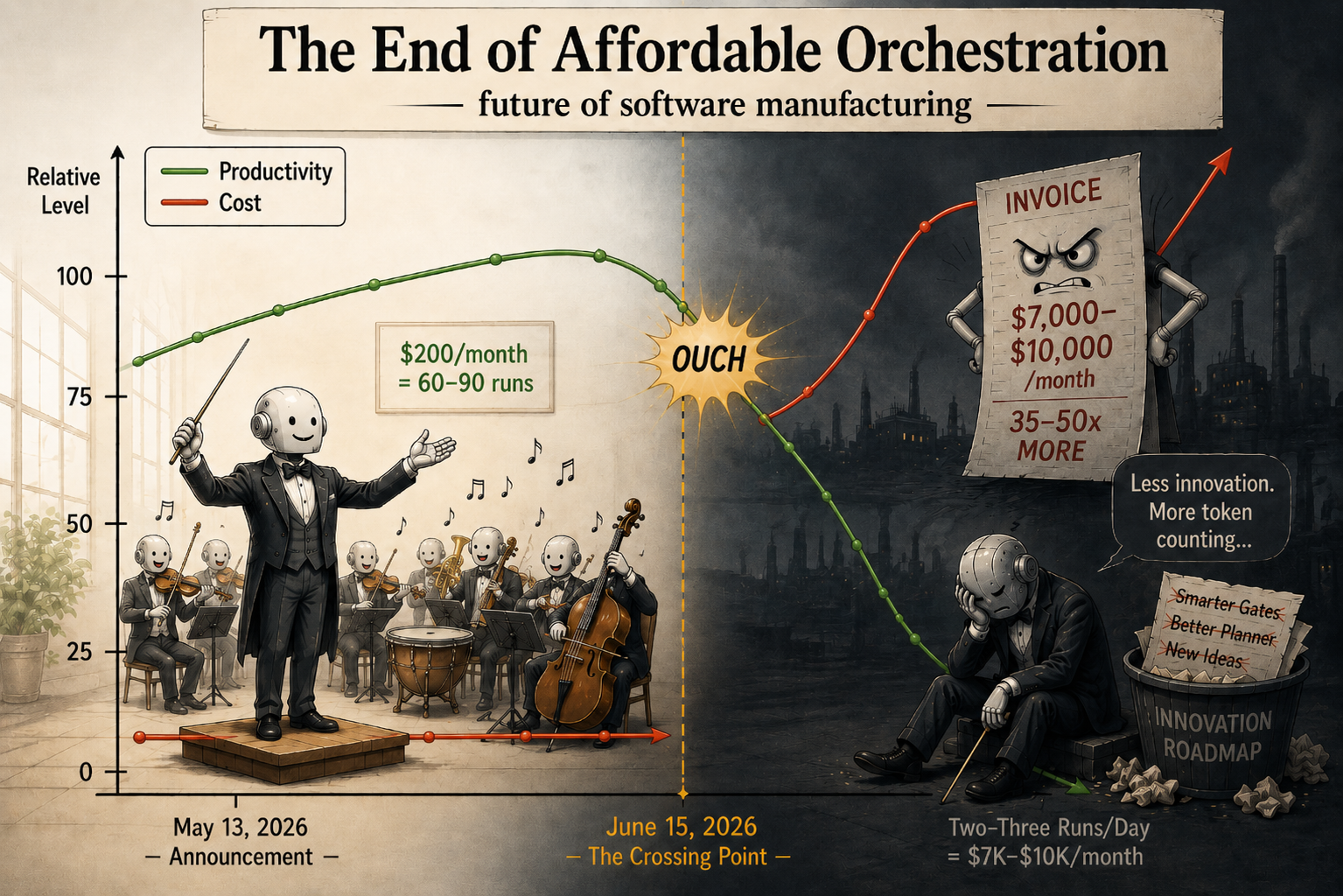
On May 13, 2026, Anthropic announced that starting June 15, programmatic Claude usage (claude -p, Agent SDK, GitHub Actions) moves to a separate monthly credit at full API token rates. Framework: set-core. Author: setcode.dev.
Bottom line
Affordable multi-agent orchestration is over.
We ran the numbers on two real production runs, both on Opus 4.6 (the model we use for orchestration; we showed in an earlier article that 4.7 is not suitable). A simple six-page website, fully tested and gate-verified with zero human labor: $93. A full webshop with Stripe, i18n, and 26 merged changes: ~$1,275. The Max 20x plan’s $200 monthly credit covers two simple sites and nothing more.
These numbers are still far cheaper than human labor for equivalent quality (a freelancer billing the same scope with the same test coverage would charge $4,000-18,000). But the orchestration was previously included in a $200/month subscription. That era is over.
And it’s not just about the money: when every agent dispatch has a price tag, the entire incentive structure of orchestration development inverts. The pressure shifts from building better frameworks to building cheaper ones.
What claude -p is and who uses it
claude -p is Claude Code’s non-interactive mode. You give it a prompt, it runs, outputs results, exits. No human in the loop. It has the same tools as interactive Claude Code (file read/write, bash, git, search, edit), but it runs headless.
In just over a year it became the backbone of a surprising range of automation:
- CI/CD pipelines. PR review bots, automated code review on push, security scanning, dependency audits, release note generation. Claude reads the diff, writes comments, or opens follow-up PRs.
- Scheduled maintenance. Nightly doc sync, weekly dependency updates, morning PR triage. Cron jobs that dispatch
claude -pwith a task. - Multi-agent orchestration. Frameworks like set-core, claude-flow, and custom orchestrators dispatch N parallel agents via
claude -p, each in its own git worktree, with structured verify gates and serial merge. This is the highest-volume use case. - Data processing. Log analysis, CSV transformation, structured extraction piped through
claude -pas a Unix-style utility. - Code migration. Fan out a migration task to dozens of
claude -pinstances, each handling a file or module.
The common factor: all of these are automated, non-interactive, and high-volume. Exactly the usage pattern the new billing targets.
What $200/month bought us until now
A Claude Max 20x subscription costs $200/month. For that, we got unlimited claude -p calls alongside interactive Claude Code. In practice, this is what our production month looked like:
- 2-3 full orchestration runs per day. Each run takes a spec, decomposes it into 5-6 parallel changes, dispatches agents to separate git worktrees, runs verify gates (build, test, lint, e2e, review, scope check), and merges them serially into main.
- 60-90 runs per month. Some days more (active development), some less (review days). Call it 75 runs as a working average.
- Every agent dispatch is a
claude -pcall. The planner, the feature agents, the review gates, the verify retries, the merge-queue integration checks: all non-interactive.
The subscription absorbed all of this. No metering, no per-token billing, no overage. The marginal cost of one more agent dispatch was zero. We optimized for code quality, not token count.
What the same workload will cost starting June 15
We took two real production runs from the past two weeks and computed what they cost at current Opus 4.6 API rates ($5/MTok input, $25/MTok output, $0.50/MTok cache read, $6.25/MTok cache write).
What these runs deliver
Before the numbers: what you get for the money matters. These are not “generate some code and hope for the best” runs. This is what the future of software manufacturing looks like: a fully automated, zero-human-labor pipeline:
- The planner decomposes the spec into parallel changes
- Each change runs in its own git worktree
- Every change passes through 10+ quality gates: build, lint, unit tests, E2E tests, scope check, spec coverage, design fidelity, code review (LLM), spec verification (LLM), rules compliance
- Failed gates trigger automatic retries with structured feedback
- Passing changes merge serially into main through an integration queue that re-runs gates against the updated codebase
- The output is a production-ready, tested, reviewed branch — the only human step is a final review before deploy
No developer writes code. No reviewer reads diffs. No QA runs tests. The entire pipeline from spec to merged main is automated. A lights-out software factory. The cost below is the price of running it — and starting June 15, Anthropic is putting a meter on it.
Run 1: A simple website — $93
A straightforward marketing site: home, about, blog (list + detail + filter), contact wizard with validation. 6 changes, all merged. All Opus 4.6. Total active time: 80 minutes. Zero human intervention.
| Change | Output tokens |
|---|---|
| Foundation and navigation | 203,783 |
| Home and about pages | 57,100 |
| Blog listing and filter | 108,495 |
| Contact wizard | 72,670 |
| Blog detail and tests | 52,609 |
| Blog extras and acceptance | 98,130 |
| Output tokens | 592,787 |
| Quality gates per change | 10+ |
| Human labor | 0 |
| Run total | $92.52 |
A simple website. Six pages. 10+ gates per change. Eighty minutes. Zero human labor. $93.
Run 2: A complex webshop — $1,275
A full e-commerce platform: product catalog, shopping cart, Stripe checkout, webhook payment processing, order fulfillment, email notifications, i18n, legal pages, SEO. 26 changes, all merged. Mix of Opus and Sonnet. Zero human intervention.
| Changes merged | 26 |
| Active compute time | ~7 hours |
| Quality gates passed | 260+ (10+ per change) |
| Human labor required | 0 hours |
| Estimated cost at current rates | ~$1,275 |
One orchestration run. One production-ready webshop. Every page tested, every flow verified, every change code-reviewed by LLM. Seven hours of compute. ~$1,275.
For context: a freelance developer building the same webshop with the same quality gates (unit tests, E2E, code review, integration testing) would bill 80-120 hours at $50-150/hour. That’s $4,000-18,000. The orchestration does it in 7 hours for $1,275 with zero human labor.
The numbers
| Simple website | Complex webshop | |
|---|---|---|
| Changes | 6 | 26 |
| Active compute time | 80 min | ~7 hours |
| Quality gates per change | 10+ | 10+ |
| Human labor | 0 | 0 |
| Cost at API rates | $93 | ~$1,275 |
The new credit structure:
| Plan | Monthly credit |
|---|---|
| Pro ($20/mo) | $20 |
| Max 5x ($100/mo) | $100 |
| Max 20x ($200/mo) | $200 |
Credits don’t roll over. When depleted, you pay standard API rates as overage (if enabled).
At these rates:
| Scenario | Monthly API cost | Minus $200 credit | Before June 15 |
|---|---|---|---|
| 2 simple sites/week | $742 | $542 | $0 |
| 1 simple site/day | $2,776 | $2,576 | $0 |
| 1 webshop/month | $1,275 | $1,075 | $0 |
| Production (1 site/day + 1 webshop/month) | $4,051 | $3,851 | $0 |
The $200 monthly credit covers about two simple site runs. A production team doing daily orchestration faces $2,500-4,000/month in new costs. Still far cheaper than human labor for equivalent quality — but no longer free.
Where the money goes
The dominant cost is not output tokens (the code the agents write). It’s the input context — the project knowledge that every agent dispatch consumes. Every time an agent starts work, it ingests CLAUDE.md, rules, relevant source files, conversation history. Prompt caching helps (repeat context is 10x cheaper), but cache expires after 5 minutes. If a build or test run takes longer than that, the next agent call re-ingests everything at full price.
In the simple website run, output tokens (the actual generated code) accounted for only 16% of the cost. The rest was context.
The workaround question
The split is between “interactive” (stays on subscription) and “programmatic” (claude -p, billed from credit). The obvious workaround: run orchestration through interactive sessions instead of claude -p.
Whether this lasts depends entirely on whether Anthropic chooses to detect it. The distinction exists because multi-agent orchestration consumes orders of magnitude more resources per subscriber than single-user interactive sessions. Anthropic built this billing split for a reason. If workarounds become widespread, they’ll close them. If they don’t bother, the workaround holds.
Betting your production infrastructure on a billing loophole that the provider has every incentive to close is not a strategy. It’s a grace period.
The realistic options:
- API key. Skip the subscription credit entirely. Same rates, no ceiling. Access to Batch API (50% discount) for non-time-critical work.
- Model tiering. Not every agent call needs Opus. Sonnet for reviews, Haiku for classification. Cuts the blended rate.
- Cache management. Keep agents within the 5-minute cache TTL to minimize re-ingestion of project context. This is the single biggest lever on input cost.
- Accept the cost. If orchestration saves enough engineering hours, $7K-10K/month is still cheaper than the equivalent human labor.
The API escape hatch: real or mirage?
The obvious question: if claude -p is now metered at API rates, why not skip Claude Code entirely and call the Anthropic Messages API directly with your own API key?
What’s metered and what’s not
| Channel | Billing source | Built-in tools? |
|---|---|---|
| Interactive Claude Code (terminal, IDE) | Subscription (unchanged) | Yes |
claude -p (non-interactive) |
New programmatic credit → API overage | Yes |
| Claude Agent SDK | New programmatic credit → API overage | Yes |
| Claude Code GitHub Actions | New programmatic credit → API overage | Yes |
| Third-party agents via sub auth (pi.dev, OpenClaw, etc.) | New programmatic credit → API overage | Depends on tool |
| Direct Anthropic API (Messages API, own key) | API account, no subscription | No |
The Agent SDK falls under the same credit system as claude -p. Using it instead of claude -p changes nothing about cost.
The third-party agent trap
This deserves its own section because the history matters.
Until April 2026, third-party coding agents like pi.dev and OpenClaw could authenticate against a Claude subscription (via CLI auth token) and run on the subscriber’s plan. Same unlimited pool as interactive Claude Code. This was compute arbitrage: a $20 Pro subscription could run agent workflows that would have cost $500+ on a direct API key.
In early April, Anthropic banned third-party agent usage on subscriptions outright, citing capacity issues. The OpenClaw community erupted. Six weeks later, on May 13, Anthropic reversed the ban but introduced the Agent SDK credit system as the catch: third-party tools are welcome again, but they draw from the new separate credit, at API rates.
So yes: pi.dev with Claude subscription auth falls under the exact same credit ceiling. $200/month on Max 20x, then API-rate overage. The same constraint that hits claude -p orchestration hits every third-party agent that authenticates via subscription.
The only path that avoids the credit: direct API key
Only the raw Anthropic Client SDK (direct client.messages.create() calls with your own API key) or a third-party agent configured with a direct API key sidesteps the subscription credit entirely. You pay API rates from your API account. No $200 monthly ceiling, no overage toggle. Just usage-based billing.
The token rates are identical either way. Opus 4.6 costs $5/MTok input and $25/MTok output whether you call it through claude -p, through pi.dev on subscription auth, or through a raw API call. The new billing doesn’t make programmatic usage more expensive than direct API. It makes it cost the same as direct API. Before June 15, subscription-authenticated programmatic usage was subsidized. After, the subsidy is gone. The underlying cost was always this high.
pi.dev + API key: the middle path
Here’s where it gets interesting. If you use pi.dev (or a similar open-source coding agent) with a direct Anthropic API key instead of subscription auth:
- No credit ceiling. You pay for what you use, no $200/month cap.
- No subscription required. You don’t need Max 20x. You don’t need any Claude plan.
- Full agent runtime. pi.dev provides its own tool infrastructure: file read/write, bash execution, git operations, sub-agents, plan mode, permission gates, MCP integration. You don’t need to build these yourself.
- 15+ model providers. Anthropic, OpenAI, Google, Bedrock, Ollama, OpenRouter. Switch between models per task, or run local models for sensitive code.
- Same token rates. $5/$25 for Opus through Anthropic API. Potentially different rates through Bedrock or Vertex.
- Open source (MIT). No vendor lock-in. No terms-of-service surprises.
This is the path that didn’t exist before the billing split mattered. When claude -p was subsidized, nobody cared about alternatives: why pay API rates when the subscription covered everything? Now that everyone pays API rates regardless, the question flips: why pay for Claude Code when an open-source agent gives you the same tools at the same price without a subscription?
What you lose leaving Claude Code
- Anthropic’s prompt caching optimization. Claude Code manages cache breakpoints automatically. pi.dev and other agents manage their own caching, with varying sophistication.
- CLAUDE.md, rules, skills, hooks. Claude Code’s project-context system. pi.dev has its own equivalents (extensions, prompt templates, skills) but migration is manual.
- Session management. Context compaction, conversation history, session resume/fork.
- First-party integration velocity. Claude Code ships features that work with the latest Anthropic models immediately. Third-party agents lag.
Where this leads
Claude Code’s value proposition for orchestration was never stated explicitly, but it was obvious: unlimited agent dispatches for a flat monthly fee. Direct API for the same workload would have cost $7K-10K/month all along. Nobody used direct API (or pi.dev with an API key) for heavy orchestration because subscription-auth claude -p was effectively free.
Remove the subsidy, and the calculus changes. If the price is the same everywhere, the choice becomes about capability, flexibility, and lock-in, not cost.
The likely trajectory:
- Short term (June-August 2026). Most users stay on
claude -por Agent SDK. The $200 credit covers light usage. Switching cost is too high for an immediate move. - Medium term (Q3-Q4 2026). Heavy orchestration users migrate to direct API keys, either through pi.dev, custom harnesses, or raw Client SDK. They gain model flexibility, no credit ceiling, and access to Batch API (50% discount for non-real-time work).
- Long term. Claude Code becomes the interactive IDE tool. Orchestration moves to API-key-based agents (pi.dev, custom frameworks, or Anthropic’s own Managed Agents), where billing is transparent and the framework controls the full stack.
Or Anthropic introduces an orchestration tier, adjusts credit amounts, or competitors offer better terms, and the whole calculation changes. The one certainty is that the flat-fee era for programmatic AI usage is over.
The perverse incentive: innovation vs. token count
This is the part that concerns us more than the dollar amount.
Until June 14, the economics of orchestration development were simple: the subscription was a fixed cost. Every hour went into making the framework better. We spent months building a 13-role model resolver, a 5-tier priority chain, structured verify gates, scope-check gates, design-fidelity checks, spec-coverage tracking. Every new feature made the orchestration more reliable, the output higher quality, the failure modes more visible.
All of that costs tokens. A review gate that catches a subtle bug costs tokens. A scope-check that prevents an agent from wandering outside its spec costs tokens. A verify-retry that forces an agent to fix a failing test costs tokens. We built these features because the subscription model gave us room to experiment, iterate, and push the boundaries of what orchestration could do.
Starting June 15, every one of those features has a dollar sign on it. And the development roadmap shifts from “what should we build next?” to “what can we afford to run?”
The rational response to per-token billing is to minimize tokens. That means:
- Fewer verify gates. Skip the review gate, skip the scope check, skip the design-fidelity comparison. Each gate saved is thousands of tokens saved.
- No retries. If the first attempt passes build, ship it. Don’t run the spec-verify gate that might flag a subtle mismatch and trigger a retry.
- Dumber decomposition. Don’t use a three-phase planner (brief → domain → merge) for complex specs. Use a single LLM call and accept rougher boundaries. Fewer planner tokens, more merge conflicts, but cheaper.
- Smaller context. Strip the CLAUDE.md, reduce the rules, give agents less project context. They’ll make worse decisions, but they’ll make them with fewer input tokens.
- No exploratory agents. Don’t dispatch a canary agent to test an approach before committing to it. Just commit to the first plan and hope it works.
Every one of these saves money. Every one of them takes the framework backward.
The development trajectory inverts. The time that went into building new capabilities (better planners, smarter gates, richer verification) now goes into cutting token costs. The roadmap conversation stops being “what should the next gate check for?” and becomes “which existing gates can we strip out?” Innovation doesn’t stop because the ideas dry up. It stops because every experiment costs real money to run, and the budget pressure pushes toward the cheapest thing that still works.
The logical endpoint of pure token-cost optimization is no orchestration at all. A single agent, one claude -p call, no gates, no verification, no parallel worktrees. Raw code generation into main. That’s 2024-era agentic development, which is exactly what orchestration was built to replace.
This is not theoretical
We have concrete data from our own framework. In our earlier article, we showed that Opus 4.7’s “creative” planner produced 12 changes instead of 5 on the same spec, at 2.17x the token cost. The 4.7 planner was better at decomposition in a single-agent sense (finer granularity, standalone test changes, more focused scopes). It was worse for orchestration because the overhead per change (dispatch, gates, merge) compounded.
Under subscription pricing, we chose 4.6 because it produced better orchestration outcomes: fewer failure surfaces, less scope wandering, more predictable merges. Under per-token pricing, the same choice happens to also be the cheaper one. But that’s a coincidence. The general incentive is clear: when tokens cost money, the pressure is to minimize tokens, not to push the framework forward.
Where this leads
Orchestration frameworks will split into two tracks:
- Cost-optimized. Minimum gates, minimum context, minimum retries. Fast, cheap, lower quality. Fine for prototypes, landing pages, boilerplate. The “assembly line” tier.
- Quality-optimized. Full gate stack, rich context, structured verification. Expensive, reliable, higher quality. For production code that has to work. The “engineering” tier.
The subscription model funded the engineering tier at assembly-line prices. That’s over. The choice is now explicit, and the budget pressure will push most teams toward the assembly line. Not because the engineering tier stopped being valuable, but because the room to build it just got a lot more expensive.
Caveats
Dollar estimates use current published API rates. Anthropic could adjust rates, credit amounts, or overage terms before or after June 15.
Two runs is a small sample. Different project types will produce different cost profiles. The common factor is that uncached input dominates.
The “interactive vs. programmatic” boundary is Anthropic’s to define and could shift at any time.
Competing providers may respond. If Google, OpenAI, or others offer more favorable orchestration tiers, the relative economics shift.
Cache behavior varies. Better cache management would reduce costs. The 5-minute TTL is the constraint; frameworks that keep agent calls within that window pay significantly less for input context.
The innovation-vs-cost tension is not new. Software has always had this tradeoff. What’s new is that it now applies within the AI tooling layer, not just between human labor and automation. The subscription model temporarily removed the constraint; per-token billing puts it back.