This is Part 2 of a series. Part 1 traced the architecture of frontier coding agents. This article follows a different thread: what happens when the same architecture gets recommended to everyone, by the same models, through the same mechanisms. Framework: set-core. Author: setcode.dev.
Why I am writing this
I use orchestration as my example throughout this article because I build orchestration systems and I know the domain. But this is not an article about orchestration. The mechanism I describe applies to every pattern AI recommends: RAG with vector databases for search, microservices for scaling, React for frontends, Kubernetes for deployment, event-driven architecture for decoupling. Pick any trending pattern. The same loop runs on all of them.
I am writing this because I can see it happening from the inside. When you build something from scratch, from production failures and redesigns, you develop a sense for the difference between someone who understands a pattern and someone who received a recipe. That difference is becoming harder to spot, because the recipes look increasingly professional. And the source of those recipes, the AI itself, is gradually losing access to the reasoning that made the patterns worth recommending in the first place.
That last part is the one that concerns me most.
What I see
I have been building an orchestration system since November 2025. Not from a tutorial. Not because an AI recommended it. From production failures, redesigns, discarded approaches. Every decision in the system traces back to a specific failure I experienced.
While building, I watch what happens around me. Every month, more people write “agentic orchestration” posts. More people build governor patterns, verify gates, context management layers. Almost identically. Not because they all reached the same conclusion independently. Because they asked the same AI.
The patterns work. Orchestration works. Governors work. The solutions are not bad.
The problem is that with each copy, the understanding degrades. And eventually, the AI itself can no longer tell the difference between a well-understood pattern and a cargo-culted one.
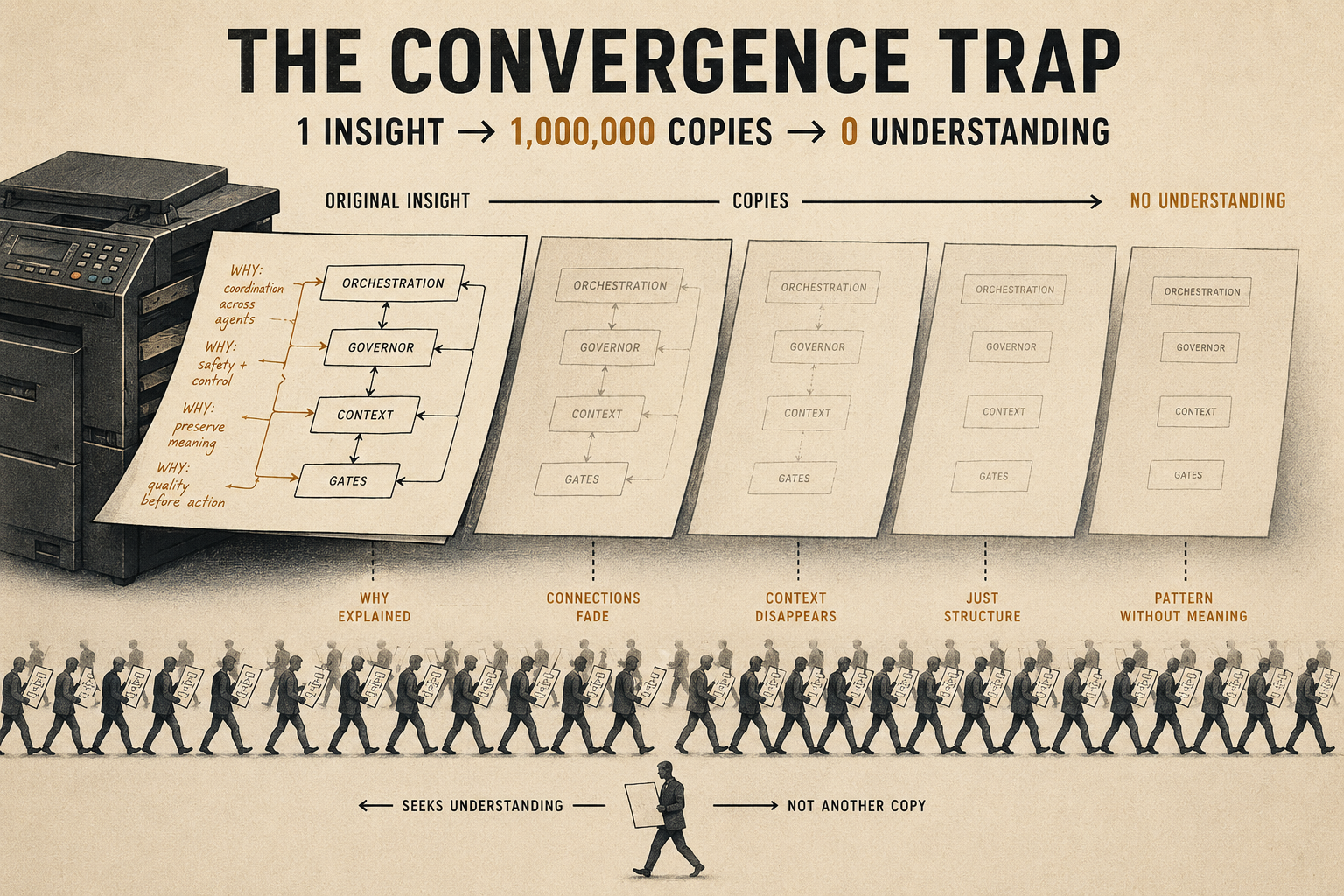
How one person’s insight becomes a million copies
It starts with real pain
A developer hits a production failure. Agents run without coordination, overwrite each other’s work, produce contradictory outputs. The developer builds an orchestration layer. They understand exactly why each component exists, because they lived through the failure that made it necessary. They write about it. They push the code to GitHub.
I know this part because I lived it. November 2025, agents stomping on each other’s changes, corrupting shared state, producing outputs that contradicted each other within the same run. The governor pattern was not an architectural choice from a textbook. It was a direct response to watching three agents destroy each other’s work in real time.
The context gets stripped
The blog post gains traction. Tutorials reference it. Stack Overflow answers cite it. The GitHub repo accumulates stars.
The pattern enters the training data of the next model version. But the training process does not preserve context. The model does not learn “this developer solved this specific coordination problem with this specific design after experiencing this specific failure.” It learns a statistical association: “orchestration layer is what you build for agent systems.”
The pain is gone. The specificity is gone. What remains is a template.
The copies flood in
Hundreds of developers receive this template from AI. Many of them implement it, ship it, and write about it. Their blog posts, their GitHub repos, their Stack Overflow answers look indistinguishable from expert content. The structure is correct. The terminology is correct. The reasoning is absent.
I see these posts regularly now. I can tell the difference because I know which failure mode each component addresses. The posts describe the what perfectly. They almost never describe the why. Not because the authors are hiding it, but because they never had it. The AI gave them the structure. Nobody gave them the history.
The signal drowns
Here is where it gets worse. Those copies go back into the training data. The model cannot distinguish between the original (written by someone who understood the failure mode) and the copies (written by people who received a recipe). It weights them equally. As copies outnumber originals, the training data shifts toward recipe-level understanding.
The nuances erode: when not to use the pattern, which failure modes it does not cover, which simpler alternatives work better for smaller projects. A 500-line CLI tool does not need a governor. But the AI does not ask how big your project is. It recommends the full pattern, because that is what the training data says works.
This is not a theoretical concern. The GitClear 2025 report analyzed 211 million changed lines of code between 2020 and 2024. Copy-pasted code increased 48%. Duplicated code blocks grew eightfold. Refactoring dropped from 25% of all changes to below 10%. Code that gets rewritten within two weeks nearly doubled. The industry is copying more and understanding less, and the data shows it.
Why the AI cannot fix this on its own
This is the part that keeps me up at night. The problem is not just that humans lose understanding. The problem is that the AI itself is losing access to the original reasoning.
The rating game
I have experienced this firsthand. When I ask Claude or GPT to help me build something simple, it recommends the complex version. Every time. A small data pipeline? Here is an event-driven architecture with message queues. A config file parser? Here is a plugin system with dependency injection. The AI cannot help it.
There is a structural reason. When the model is trained, human raters compare pairs of answers. “Build an orchestration layer with a governor pattern” versus “Write a script, that is enough for this case.” The comprehensive answer wins. Every time. Nobody gets fired for recommending enterprise architecture. The simple answer looks lazy, even when it is correct.
Research confirms the intuition. A 2024 study on RLHF alignment showed that the standard training process causes “preference collapse”: minority preferences get virtually disregarded. The simple, context-appropriate answer is a minority preference. The complex answer is the majority preference. The training amplifies the majority and suppresses the minority.
The result: the model systematically over-recommends complex patterns, regardless of the situation. Not because it evaluated your project and decided you need a governor. Because its training made the simple answer almost impossible to surface.
Popularity is not correctness
The model learned from GitHub, Stack Overflow, blog posts. This corpus is not a balanced sample of good engineering decisions. It is popularity-weighted. A repository with 10,000 stars generates more training signal than one with 3 stars. Stars measure marketing, timing, and trend alignment. They do not measure correctness.
I have seen elegant, simple solutions in obscure repos that solve specific problems better than any popular framework. The AI will never recommend them. Their signal is invisible against the noise of popular alternatives.
A 2024 study at ACM Creativity & Cognition measured what happens: users working with an LLM generated more ideas, but less distinct ones. The homogenization is group-level. The model suggests similar solutions to different users. Individual creativity may increase. Collective diversity decreases.
The original ideas disappear
This is the part I keep coming back to. A 2024 Nature paper demonstrated that training a model on its own output causes irreversible damage. The tails of the distribution disappear. Rare but valid approaches vanish from the model’s repertoire.
Think about what that means in practice. Somewhere, someone built a coordination system that did not use orchestration. Maybe they used a shared blackboard pattern instead. Maybe they used a market-based approach where agents bid on tasks. Maybe they solved it with something nobody else thought of. Those solutions exist in old repos, in forgotten blog posts, in conference talks from 2023.
But the training data is now saturated with orchestration content. The alternative approaches are statistically invisible. The model has lost access to them, not because they were deleted, but because they were drowned. The next developer who has a problem that would be better solved by a blackboard pattern will get an orchestration recommendation instead. And they will never know there was a better option.
The AI is not just giving everyone the same answer. It is losing the ability to give a different one.
Why this matters beyond code
Half-knowledge is worse than ignorance. I keep saying this because I keep seeing it play out.
Ignorance is cautious. A developer who knows they do not understand orchestration will ask questions, read documentation, test carefully. Half-knowledge is dangerous because it feels like knowledge. The system works. The tests pass. The architecture looks professional. The developer believes they understand it, because it runs.
The gap appears when something breaks in a way the recipe does not cover. A failure mode the governor was not designed for. A scaling problem the original author solved with a specific tradeoff that never made it into the AI’s recommendation. At that point, the developer cannot reason about the system. They knew how. They never learned why.
The Fastly/Stack Overflow data from 2025-2026 shows this split clearly. Senior developers (10+ years) trust AI output at face value 39% of the time, yet 32% of their shipped code is AI-generated. Junior developers (0-2 years) trust AI at face value 78% of the time, yet only 13% of their shipped code is AI-generated. Seniors trust less but ship more, because they have the understanding to evaluate the output. Juniors trust more but ship less, because when bugs appear downstream, they cannot debug what they never understood.
The circle closes
This brings me to the question I started with: why are there so many failed AI projects, and why is there a growing AI-skeptic movement?
The mechanism explains both.
Organizations adopt AI tools. Developers receive patterns from the model. They implement them without deep understanding. They ship systems that look correct but are fragile. When those systems fail under conditions the recipe does not cover, the project is declared a failure. McKinsey: 88% of companies use AI in at least one function. Only 39% see EBIT impact, mostly below 5%. An NBER study surveying 6,000 executives: 69% of firms actively use AI, 90%+ report no impact on productivity over three years.
Developers who watched these projects fail, who debugged AI-generated code that looked right but was not, who spent more time reviewing AI output than writing code from scratch, conclude that “AI does not work.” They are not wrong about their experience. They are wrong about the cause. The AI gave correct patterns. The understanding did not transfer. And the AI itself is progressively less able to supply the understanding, because the training data that once contained it is being diluted with every cycle.
Both the failed projects and the skeptics are consequences of the same loop. Not victims of bad technology. Victims of a knowledge-distribution system that strips the reasoning from the knowledge it distributes.
This is AI slop in its deeper form. Not bad code. Empty thinking behind correct-looking code. Surface that resembles depth.
What I take from this
I build orchestration systems. The convergence validates the patterns I use. They work. The research confirms it. The teams reporting 5-10x productivity multipliers all use structured orchestration.
But the convergence also means that having the pattern is no longer the advantage. The AI gives it away for free. Everyone has it now.
The advantage is knowing why each component exists, which failure modes it addresses, and when to not use it. That knowledge comes from building, failing, and rebuilding. Not from a prompt response. And it is the one thing the AI is becoming less able to teach, because the original sources of that knowledge are being buried under a million copies that preserved the structure and lost the reasoning.
A few of us who build this every day can see it happening. That is why I wrote this.
Part 1 traces the architecture of frontier coding agents. The amplifier paradox follows the productivity data across nine studies and 100,000+ developers.