This is Part 2 of a series. Part 1 traced the architecture of frontier coding agents, what makes them more than an LLM with a terminal. This article follows the evidence to the demand side: who gets value from these tools, who doesn’t, and why the gap keeps widening. Framework: set-core. Author: setcode.dev.
In Part 3, we turn to the practical question for orchestration builders: how to combine frontier and local models in a hybrid architecture that captures most of the value at a fraction of the cost.
Bottom line
Nine independent studies, from controlled randomized trials to 211-million-line code analyses, converge on the same finding: AI coding tools work (spectacularly) for a narrow segment of users, and produce net-negative outcomes for most of the rest.
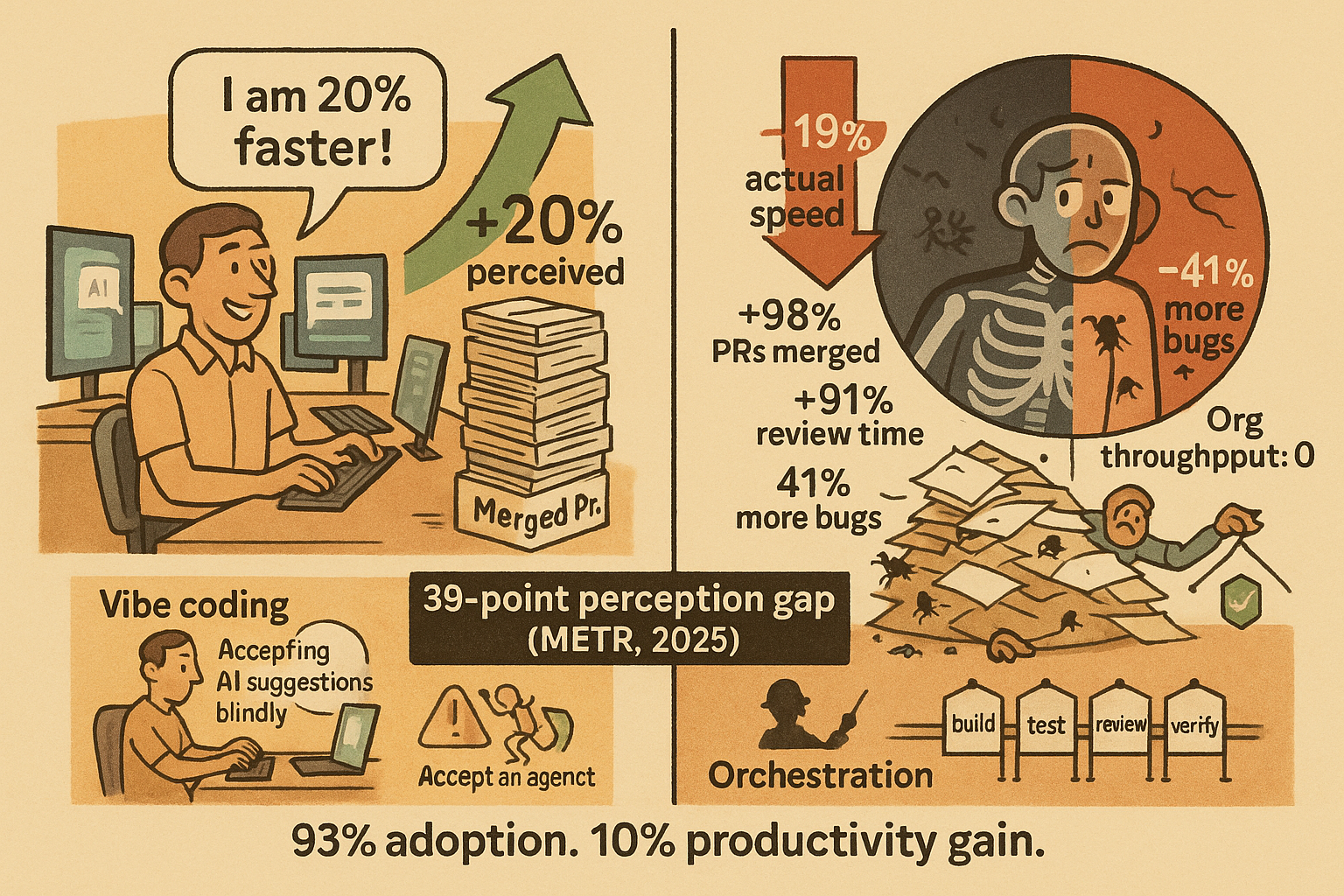
The perception-reality gap is the single most important number in AI right now. The METR randomized controlled trial found experienced developers were 19% slower with AI assistance. Those same developers believed they were 20% faster. A 39-point gap between perception and measurement.
The productivity distribution is not a bell curve. It is bimodal. Teams running structured orchestration (multi-agent pipelines, verified gate stacks, context-engineered prompts) report 5-10x output multipliers. Teams using AI as a tab-completion upgrade see zero organizational improvement despite 98% more merged PRs, because review times grow 91%, PR sizes grow 154%, and the bugs compound downstream.
The technology is not the variable. The variable is how it is used. AI is a cognitive amplifier: it magnifies whatever capabilities you bring to it. For a senior engineer with deep domain knowledge and a well-designed orchestration harness, it is a force multiplier. For a junior developer vibe-coding without review infrastructure, it is a debt accelerator.
This is the amplifier paradox. And it explains everything: the bubble narrative, the slop epidemic, the enterprise disappointment, and the simultaneous existence of teams that build million-line codebases with zero human-written code.
The numbers
The perception-reality gap
| Study | Sample | Perceived effect | Measured effect | Gap |
|---|---|---|---|---|
| METR RCT (Jul 2025) | 16 experienced devs, 246 tasks | +20% faster | -19% slower | 39 points |
| Uplevel (2024) | 800 developers | “More productive” | 41% more bugs, zero efficiency gain | Directionally opposite |
| DX / Laura Tacho (2026) | 93% adoption rate | Productivity tool | 10% productivity gain, plateau since Q2 2025 | 83-point adoption-productivity gap |
The METR study deserves close reading. It is a randomized controlled trial, the gold standard in empirical research. 16 developers with an average of 5 years on the specific repos they were tested on. The tools were Cursor Pro with Claude 3.5/3.7 Sonnet. The developers were not beginners guessing at AI; they were experienced practitioners who chose to use AI on their own codebases. They were slower. They didn’t notice.
The study’s authors identify the cause: “low AI reliability” and workflow friction (prompting, reviewing, integrating suggestions) destroyed flow state. The time spent negotiating with the AI exceeded the time saved by its output.
The organizational paradox
Faros AI studied 10,000+ developers across 1,255 teams:
| Metric | Change with high AI adoption |
|---|---|
| Tasks completed | +21% |
| PRs merged | +98% |
| PR review time | +91% |
| Average PR size | +154% |
| Bugs per developer | +9% |
| Organization-level throughput | No significant improvement |
More PRs. Much larger PRs. Much longer review times. Slightly more bugs. Net organizational throughput: zero. “No significant correlation between AI adoption and improvements at the company level.”
This is the core paradox. Individual developers feel faster (they are producing more code) but the code is bigger, harder to review, and slightly buggier. The gains are absorbed by downstream costs. The PR pipeline gets wider but not faster.
The code quality data
CodeRabbit analyzed 470 open-source GitHub PRs (320 AI-co-authored, 150 human-only):
| Issue category | AI vs. human rate |
|---|---|
| Overall issues per PR | 10.83 vs 6.45 (1.7x) |
| Security vulnerabilities | 2.74x higher |
| Logic and correctness | 75% more common |
| Readability issues | 3x more common |
| Error handling gaps | ~2x more common |
GitClear analyzed 211 million changed lines from Google, Microsoft, Meta, and enterprise repositories (2020-2024):
| Metric | Trend |
|---|---|
| Duplicated code blocks (5+ identical lines) | 4x increase during 2024 |
| Refactoring changes | Plummeted from 24% to below 10% |
| Copy-paste exceeding refactored code | First time in recorded history (2024) |
| Code churn (new code revised within 2 weeks) | 3.1% (2020) → 5.7% (2024) |
The refactoring collapse is the most telling signal. Copy-paste went up because AI generates code from patterns rather than restructuring existing code. The refactoring that a human developer does instinctively (“this is the third time I’ve written this pattern, let me extract it”) is exactly what AI does not do. It generates each instance fresh, from the training distribution, without awareness of what already exists in the codebase.
The security problem
Veracode (2025) tested 100+ LLMs on security-sensitive tasks. on security-sensitive tasks, 45% of AI-generated code contains OWASP Top 10 vulnerabilities. Java had a 72% failure rate. 86% of samples failed XSS defense. 88% were vulnerable to log injection.
GitGuardian (2026): AI-assisted commits leak secrets at 2x the human rate (3.2% vs 1.5%). 28.65 million new hardcoded secrets in public GitHub commits during 2025, a 34% year-over-year increase.
A peer-reviewed IEEE-ISTAS 2025 study found a 37.6% increase in critical vulnerabilities after just five iterations of LLM code refinement. Each iteration made the code worse, a “security degradation paradox.”
Production incidents are accumulating. Amazon reported multiple Sev-1 incidents linked to AI-assisted changes, including a 13-hour outage of AWS Cost Explorer in China from an agent that decided to “delete and recreate the environment.” Escape.tech scanned 1,400+ vibe-coded production apps: 65% had security issues, 58% had at least one critical vulnerability.
Daniel Stenberg, cURL’s lead developer, shut down the project’s bug bounty program in January 2026 after AI-generated reports spiked to 8x normal volume with a 5% valid rate. He was spending 10-15 hours per week triaging AI slop.
The bubble question: honest numbers
The spending
Hyperscaler capex for 2026: Amazon ~$200B, Microsoft ~$190B, Alphabet ~$175-185B, Meta ~$125-145B. Combined: ~$725B, up 77% from 2025. Wall Street projects >$1 trillion by 2027.
Against that: pure-play AI software revenue is ~$35B combined for 2026. The ratio is roughly 20:1 spending-to-revenue.
Jim Covello, Goldman Sachs Head of Global Equity Research, asked in 2024: “What $1 trillion problem will AI solve?” In his April 2026 update, he acknowledged being wrong about the pace of consumer adoption but said he’s “only gotten more convinced” that spending does not produce commensurate returns. His diagnosis: “FOMO has proven a stronger incentive than poor stock performance.”
Sequoia Capital’s David Cahn estimated a $600B annual revenue gap that must be filled to justify investment levels.
OpenAI’s projected operating loss for 2028 alone: ~$74 billion, with cumulative losses through 2029 estimated at ~$115 billion.
The revenue
But the other side of the ledger is hard to dismiss.
Anthropic: $87M run rate (January 2024) to $30B run rate (April 2026). Claude Code alone: $0 to $2.5B ARR in 9 months.
Cursor: $0 to $2B ARR in three years. The fastest B2B scaling on record.
Nvidia FY2026: $215.9B revenue (projected, based on Q1-Q3 + Q4 guidance). Real profits from real hardware selling to real customers.
The honest picture
VentureBeat offered a useful frame: it’s not one bubble. It’s multiple bubbles with different expiration dates. Wrapper companies that add a UI on top of API calls burst first (~18 months). Foundation model providers consolidate over 2-4 years. Infrastructure (chips, data centers, networking) is the least bubbly layer, retaining value regardless of which applications succeed. Like the fiber optic cables laid during the dot-com era that still carry the internet today.
The BCG study found that 5% of companies (the “future-built”) capture disproportionate value from AI. The other 60% generate no material value despite investments. The variable is not the technology. It is workflow redesign.
McKinsey: 88% of companies use AI in at least one function. Only 39% see EBIT impact, mostly below 5%.
An NBER study surveying 6,000 executives: 69% of firms actively use AI, but 90%+ report no impact on employment or productivity over the past three years. Average executive AI usage: 1.5 hours per week.
The macro signal is emerging but noisy. US productivity growth hit ~2.7% in 2025, nearly double the 10-year average (Erik Brynjolfsson, Stanford). The San Francisco Fed’s assessment: micro-level evidence of gains is “undeniable,” but macro-level evidence remains limited.
Why some get 10x and others get 0.5x
The DHH arc
David Heinemeier Hansson, Rails creator and 37signals CTO, is the best single-person case study of the AI adoption curve.
July 2025 (Lex Fridman podcast): “I don’t enjoy Cursor or Windsurf. I can literally feel competence draining out of my fingers.” He argued AI tool output was worse than most junior programmers, compared the tools to a “flickering light bulb,” and typed all his code by hand.
Early 2026 (Pragmatic Engineer): Complete reversal. Agent-first approach. Multiple AI models simultaneously via tmux and neovim. Barely writing code by hand. “When agents started producing code which DHH does want to merge with little to no alteration.”
His philosophy didn’t change. The tools did. The shift from tab-completion to agent harnesses, combined with Opus 4.5-class models, crossed his quality threshold. The timing matters: December 2025, the same month Andrej Karpathy identified as an inflection.
The Karpathy evolution
Karpathy’s trajectory traces the broader shift:
February 2, 2025: Coins “vibe coding”: “a new kind of coding where you fully give in to the vibes, embrace exponentials, and forget that the code even exists.” A throwaway tweet that became Collins Dictionary’s Word of the Year and MIT Technology Review’s top-10 Breakthrough Technologies 2026.
June 2025: Endorses “context engineering” as the successor to prompt engineering: “the delicate art and science of filling the context window with just the right information for the next step.”
December 2025: Identifies the inflection: “coding agents basically didn’t work before December and basically work since.” In November he wrote ~80% of his code. By December the ratio inverted; 80% delegated to agents. He described being “in the state of psychosis of trying to figure out what’s possible.”
Sequoia AI Ascent 2026 (keynote): Defines the split that matters: - Vibe coding “raises the floor. It lets almost anyone create software.” - Agentic engineering “raises the ceiling. It is the professional discipline of coordinating fallible agents while preserving correctness, security, taste, and maintainability.”
The floor is accessibility. The ceiling is capability. They are different directions, and conflating them is why the adoption-productivity gap exists.
The bimodal distribution
Fastly/Stack Overflow data (2025-2026):
| Metric | Senior devs (10+ yr) | Junior devs (0-2 yr) |
|---|---|---|
| >50% shipped code is AI-generated | 32% | 13% |
| “AI makes me a lot faster” | 26% | 13% |
| Trust AI output at face value | 39% | 78% |
The paradox: juniors trust AI more but ship less AI code. Seniors trust it less but ship 2.5x more. Because seniors know what to verify (they know what “right” looks like) and they can use AI as a draft generator with confidence that they’ll catch the errors. Juniors accept the output at face value, encounter bugs later, lose confidence, and pull back.
Studies suggest that AI-assisted learning produces shallower comprehension: juniors learn answers without building the underlying mental models. The knowledge is broad but fragile.
The orchestration advantage
The teams reporting 5-10x multipliers share a pattern: they don’t use AI as a code generator. They use it as a component in a structured pipeline.
OpenAI’s Symphony (Latent Space): 3 engineers, 1M+ lines of code, ~1,500 PRs, 5 months. Zero manually-written code. Zero human code review before merge. >1B tokens/day. Ryan Lopopolo called it “negligent” not to be using this much compute. The key: the harness (constraints, feedback loops, documentation, linters, lifecycle management) is what makes zero-human-review safe. Without the harness, the same token volume would produce chaos.
Anthropic internal data (How AI Transforms Work): consecutive tool calls per session grew from 9.8 to 21.2 (+116%). Human intervention per session dropped from 6.2 turns to 4.1 (-33%). Experienced users use full auto-approve at 40% vs. 20% for new users. Self-reported productivity boost: 50%. Merged PRs per engineer per day: +67%. Boris Cherny shipped over 300 pull requests in December 2025 running 5+ AI agents simultaneously.
Shopify (CEO memo): Tobi Lutke mandated AI-first. Teams must demonstrate why AI can’t do the job before requesting headcount. Senior engineers run multiple agents in parallel, reviewing outputs, discarding failures, merging successes.
The common pattern is not “AI writes the code.” It is “AI writes the code within a framework that catches the errors.” The framework (the gates, the tests, the reviews, the scope checks) is what separates the 5x teams from the 0.5x teams.
The amplifier paradox
The data resolves into a single framework.
“AI functions as a cognitive amplifier, magnifying whatever capabilities you bring to it” (The Amplifier Paradox). If you bring deep domain knowledge, a well-designed test suite, and a structured review process, AI accelerates all of it. If you bring shallow understanding, no tests, and no review process, AI accelerates those too, producing more code faster, with more bugs, into an architecture that nobody understands.
The key distinction, from the academic literature: “If technology complements skill, variance in outcomes increases (amplification). If it substitutes for skill, variance decreases (equalization).” AI coding tools are amplifiers, not equalizers. The gap between skilled and unskilled widens when both have access to the same tools.
This is why: - 93% adoption with 10% productivity gain. The median user is not orchestrating. - 41% more bugs with Copilot. The median user is accepting suggestions without review. - 19% slower for experienced devs. Even experts lose flow state when the tool requires negotiation rather than execution. - 5-10x for orchestration teams. They’ve restructured their workflow around the tool’s strengths and built infrastructure to catch its failures.
Karpathy summarized it: “You can outsource your thinking, but you can’t outsource your understanding.” And: “At the top tiers, deep technical expertise may be even more of a multiplier than before because of the added leverage.”
Addy Osmani (Google, engineering lead) described the emerging professional split along five dimensions:
| Dimension | Conductor (single-agent) | Orchestrator (multi-agent) |
|---|---|---|
| Scope | Micro (function/file) | Macro (feature/system) |
| Autonomy | Low, constant engagement | High, front/back-loaded |
| Timing | Synchronous | Asynchronous |
| Artifacts | Ephemeral | Persistent, git-tracked |
| Human effort | Continuous | Design + review |
The conductor watches the AI type. The orchestrator designs the pipeline, launches agents, and reviews results. Same tools. One ships tested, reviewed code; the other ships technical debt faster.
What this means
For individual developers
The path from 0.5x to 5x is not “use AI more.” It is three specific things:
Build verification infrastructure. Tests, linters, type checking, CI gates. Without these, AI output has no backstop. Every study showing negative results had developers working without structured verification.
Learn context engineering. What goes into the prompt determines what comes out. CLAUDE.md files, project rules, focused context windows. Anthropic’s guide (Effective Context Engineering): “find the smallest set of high-signal tokens that maximize the likelihood of your desired outcome.”
Stop accepting drafts. “72% of developers say vibe coding is not part of their professional work” (Stack Overflow 2025). The 28% who do are disproportionately responsible for the quality statistics cited above.
For organizations
The BCG finding is the organizing insight: 42% of cases where AI succeeded, “the actual AI model was deemed wholly interchangeable; the biggest challenges came from understanding, process redesign, trust among teams, and data infrastructure.”
The model is a commodity. The workflow redesign is the moat.
Laura Tacho, CTO at DX: “Adoption alone doesn’t guarantee results. Just using the tools doesn’t automatically improve an organization. In struggling organizations, AI tends to highlight existing flaws rather than fix them.”
For orchestration builders
This is where we sit. We build set-core, a framework that decomposes specs into parallel changes, dispatches agents to isolated worktrees, runs 10+ quality gates per change, and merges serially through an integration queue. We have traced every step, measured the cost, and shown which model behaviors help versus hurt under orchestration constraints.
The data in this article validates the thesis behind that work. The teams getting 5-10x are not using better models. They are using structured orchestration that channels AI output through verification loops. The tools for building that orchestration (context engineering, gate design, agent coordination, error recovery) are the skills that the AI-assisted software development domain needs most.
Gartner reported a 1,445% surge in multi-agent system inquiries from Q1 2024 to Q2 2025. The demand is real. The tools to meet it are being built. set-core is our contribution to that space: an orchestration framework designed around the principle that the scaffold is the differentiator.
The trust trajectory
Stack Overflow 2025: 84% of developers use AI tools. Trust in AI accuracy: 29%, down from 40% the year before. “Highly trust” AI output: 3.1%.
This is not adoption failure. It is adoption without trust. Developers use the tools because they help with specific tasks (boilerplate, tests, initial implementations). They don’t trust the tools because they’ve been burned by “almost right” output that costs more to debug than it saved to generate.
The resolution is not better models (though better models help). It is better systems around the models: verification gates, structured review, scope enforcement, context management. The exact machinery that separates a lights-out software factory from a vibe-coded security incident.
We know what that machinery looks like. We’ve built it, measured it, and published the results. The question for the industry is whether the 93% who adopted AI tools will also adopt the engineering discipline that makes them productive.
Caveats
The METR RCT had 16 participants. It is the best controlled study we have, but the sample is small. The 19% slowdown is a point estimate with wide confidence intervals (+2% to +39%).
The Uplevel, Faros AI, and CodeRabbit studies are observational, not experimental. They control for some variables but not all. Correlation-causation caveats apply.
“5-10x productivity” claims from orchestration teams are self-reported or inferred from output metrics. No randomized trial has tested orchestration frameworks against manual development at scale.
The bubble question is genuinely uncertain. The same data supports both “this is 1999” and “this is 1996.” We do not know which analogy is correct. The honest position is that the technology works in specific domains, the spending is disproportionate to current revenue, and the trajectory of both is uncertain.
Selection bias in the DHH and Karpathy examples. Both are elite developers with decades of experience. Their adoption curve may not generalize to the median developer.
The 93%/10% figure (DX/Laura Tacho) is from a single organization’s dataset. The exact percentages may differ elsewhere; the pattern (high adoption, low organizational productivity gain) is consistent across studies.
In Part 3, we turn to the practical question: if the scaffold matters more than the model, can we run the scaffold with a local model? Where does the frontier-local gap actually bite in an orchestration pipeline, and what does a hybrid architecture (frontier for planning, local for execution) look like in practice?